【2026年度版】Snowflake(スノーフレーク)とは?注目を集める理由と何がすごいのか徹底解説

この記事の結論
Snowflake(スノーフレーク)は、ストレージとコンピュートを完全分離した独自アーキテクチャを持つクラウドデータウェアハウス(DWH)です。AWS・Azure・GCPの3大クラウドに対応し、数秒単位の自動スケーリング、ゼロコピーでのデータ共有、運用工数の最大80%削減を実現します。BigQueryやRedshift、Databricksと比較して同時実行性能と運用負荷軽減に強みがあり、金融・製造・小売など幅広い業界で活用が進んでいます。
企業のデジタル変革が加速する中、データ活用の基盤として注目されるクラウドデータウェアハウス(DWH)。その中でも特に「Snowflake(スノーフレーク」という名前を耳にする機会が増えているのではないでしょうか。
「Snowflakeって何?」「何がそんなにすごいの?」「他のサービスと何が違うの?」
このような疑問を抱く方も多いでしょう。実際、従来のデータウェアハウスとは大きく異なる革新的なアプローチで、多くの企業がデータ活用の課題を解決しています。
本記事では、Snowflakeの基本から実際の活用事例まで、以下の内容を詳しく解説します。
– Snowflakeの基本概念と仕組み
– 他社サービスとの競合比較(BigQuery・Redshift・Databricks)
– コスト構造とセキュリティ機能
– 具体的なユースケースと導入事例
– 導入ステップと支援方法
特に、弊社で開発した会話型KPIダッシュボードなどの具体事例も交えながら、実際の活用イメージを持っていただけるよう説明していきます。
※本記事の情報は2025年9月時点のものです。Snowflakeの機能・料金体系・サービス内容は随時更新されるため、最新情報については公式サイトをご確認ください。導入検討の際は、必ず公式の見積もりや最新ドキュメントをご参照いただくことをお勧めします。
目次
Snowflake(スノーフレーク)とは何か
データクラウドの定義
Snowflakeは、クラウド上で提供されるデータウェアハウス(DWH)サービスです。より正確には、同社が提唱する「データクラウド」という概念の中核を担うプラットフォームです。
データクラウドとは、企業のあらゆるデータを安全に保存・処理・共有できる統合的な環境のことを指します。従来のように、データを各部門やシステムごとに分散して管理するのではなく、一元的にクラウド上で管理し、必要な人が必要な時にアクセスできる仕組みを実現します。
たとえば、営業データ、顧客データ、財務データ、マーケティングデータなど、これまで別々のシステムに保存されていた情報を、Snowflake上で統合して分析することが可能になります。
Snowflakeの基本構成と歴史
Snowflakeは2012年にアメリカで創業され、2020年に米ソフトウェア企業として史上最大のIPOを実現したクラウドデータウェアハウス企業です。現在、AWS、Microsoft Azure、Google Cloud Platformの3大クラウドプラットフォーム上で稼働しており、企業は好みのクラウド環境でSnowflakeを利用できます。
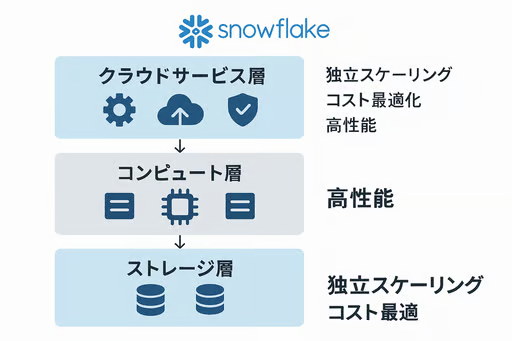
Snowflakeの基本構成は、以下の3層アーキテクチャで構成されています。
1. データベースストレージ層
– データを安全に保存する層です
– 自動的に圧縮・暗号化されます
– クラウドの標準的なストレージサービスを活用します
2. コンピュート層(仮想ウェアハウス)
– データの処理・分析を担当する層です
– 必要に応じて自動でスケールアップ・ダウンします
– 複数のワークロードを並行処理可能です
3. クラウドサービス層
– メタデータ管理、認証、最適化などを担当します
– セキュリティとアクセス制御を一元管理します
– クエリの最適化やキャッシュ機能を提供します
従来型DWHとの違い
従来のオンプレミス型データウェアハウスや、他のクラウドDWHサービスと比較して、Snowflakeには以下のような革新的な特徴があります。
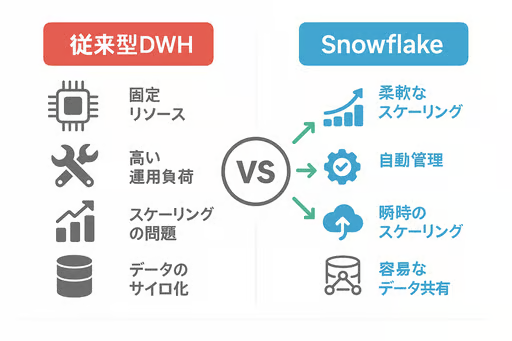
従来型DWHの課題
– 固定的なリソース:事前にサーバースペックを決める必要があります
– 運用負荷が高い:チューニングやメンテナンスに専門知識が必要です
– スケールの限界:急激なデータ増加に対応しづらい状況です
– データ共有が困難:他部門や外部とのデータ共有に制約があります
Snowflakeの革新
– 柔軟なリソース配分:ストレージとコンピュートが完全に分離され、それぞれ独立してスケール可能です
– 運用負荷の軽減:インデックス設計やパーティション設定などの複雑な作業が不要です
– 瞬時のスケーリング:数秒でコンピュートリソースを追加・削減可能です
– 簡単なデータ共有:ワンクリックで安全にデータを共有できる仕組みです
Snowflake(スノーフレーク)は何がすごい?
ストレージとコンピュートの分離アーキテクチャ
Snowflakeの最大の革新は、ストレージ(データ保存)とコンピュート(データ処理)を完全に分離した独自アーキテクチャにあります。
従来のシステムでは
データの保存場所と処理能力が一体となっており、どちらか一方をスケールアップする際に、もう一方も同時に拡張する必要がありました。これはコスト効率が悪く、リソースの無駄につながっていました。
Snowflakeでは
– ストレージ:使った分だけの従量課金で、無制限にデータを保存可能です
– コンピュート:処理が必要な時だけ起動し、処理が終われば自動停止します
– 独立スケーリング:ストレージを増やすことなく処理能力だけを向上させることが可能です
たとえば、月末の売上集計で大量のデータ処理が必要な時は、コンピュートリソースを一時的に大幅に増強し、処理完了後は元の規模に戻すことで、コストを最適化できます。
スケーラビリティと柔軟なリソース割当
Snowflakeの仮想ウェアハウス(コンピュート環境)は、以下のような柔軟性を提供します。
1. 瞬時のスケーリング
– 数秒でコンピュートサイズを変更可能です(XS → L → 4XLなど)
– 処理量に応じて自動でスケールアップ・ダウンします
– ピーク時とオフ時でリソース使用量を最適化します
2. 複数ワークロードの並行処理
– 部門ごと、用途ごとに独立した仮想ウェアハウスを作成します
– ETL処理、分析処理、レポート生成を同時実行します
– 一つの処理が重くても他に影響しないワークロード分離を実現します
3. 自動管理機能
– 一定時間使用されないと自動停止します(コスト削減)
– クエリの優先度に応じたリソース割当を行います
– メンテナンスやアップデートは自動実行されます
データ共有とMarketplace
Snowflakeのデータ共有機能は、従来のデータ連携の概念を大きく変える革新的な機能です。
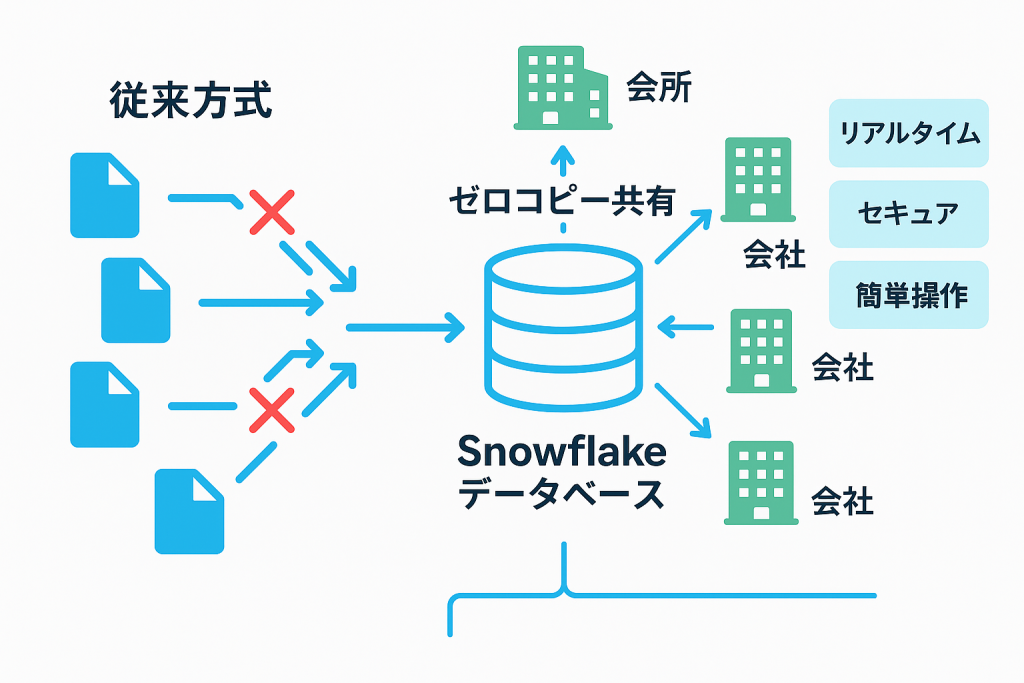
従来のデータ共有の課題
– データのコピーによる重複とバージョン管理の複雑化
– FTPやAPIを使った煩雑なデータ転送プロセス
– セキュリティリスクと管理コストの増大
Snowflakeのデータ共有
– ゼロコピー共有:データを実際にコピーすることなく、リアルタイムで共有します
– セキュアな共有:アクセス権限を細かく制御し、監査ログも自動生成します
– 簡単な操作:数クリックで外部組織とのデータ共有が可能です
Snowflake Marketplaceでは、以下のようなデータが提供されています。
– 経済指標データ(Weather Source、Economic Data)
– マーケティングデータ(広告効果、消費者行動)
– 業界固有データ(金融、ヘルスケア、リテール)
たとえば、自社の売上データと外部の経済指標データを組み合わせることで、より精度の高い需要予測モデルを構築することが可能になります。
半構造化データ・AI連携の強み
現代のデータ活用では、従来の構造化データ(CSVやRDBのテーブル形式)だけでなく、半構造化データ(JSON、XML、Parquet等)の処理も重要になっています。
Snowflakeの半構造化データ対応
– ネイティブサポート:JSONデータをそのまま格納し、SQLで直接クエリ可能です
– 自動スキーマ検出:データ構造を自動で認識し、最適化します
– 高速処理:従来のリレーショナルデータと同等の処理速度を実現します
AI・機械学習との連携
– Snowpark:Python、Scala、JavaでSnowflake上のデータを直接処理します
– Snowflake Cortex(AI/ML機能):Snowflake内蔵のAI/ML機能(自然言語処理、異常検知等)を提供します
– Snowpark:Python、Scala、JavaでSnowflake上のデータを直接処理します
– Snowflake Cortex(AI/ML機能):Snowflake内蔵のAI/ML機能(自然言語処理、異常検知等)を提供します
– 外部MLプラットフォーム連携:TensorFlow、PyTorch、scikit-learn等との連携が可能です
たとえば、ECサイトの顧客行動ログ(JSON形式)とトランザクションデータ(テーブル形式)を組み合わせて、レコメンドエンジンを構築することが、同一プラットフォーム上で完結できます。
競合比較(最新機能を反映した比較)
BigQueryとの違い(料金体系・処理特性)
Google BigQueryは、Snowflakeと並んでよく比較されるクラウドDWHサービスです。両者の主な違いを整理します。
料金モデル
| 項目 | Snowflake | BigQuery |
|---|---|---|
| ストレージ | 使用量ベース従量課金 | 使用量ベース従量課金 |
| コンピュート | 実行時間ベース課金 | クエリ処理データ量ベース課金 |
| 予約インスタンス | 年間契約で割引 | スロット予約で固定料金 |
処理特性
– Snowflake:OLAP分析に最適化され、一部トランザクションも処理可能、同時実行性能が高い
– BigQuery:大規模分析クエリに特化、Google Cloudエコシステムとの連携が強い
適用場面
– Snowflakeが有利:複数部門での同時利用、リアルタイム性重視、データ共有が重要
– BigQueryが有利:Google Cloudメイン環境、大規模バッチ処理中心、機械学習連携重視
Redshiftとの違い(クラスタ管理・運用コスト)
Amazon Redshiftは、AWSが提供するデータウェアハウスサービスです。
アーキテクチャの違い
– Snowflake:マルチクラスタ、自動スケーリング
– Redshift:従来は単一クラスタ中心だったが、現在はServerlessや自動スケーリングも提供
運用負荷
– Snowflake
– ノード管理、パフォーマンスチューニング不要です
– 自動バックアップ、自動メンテナンスを実施します
– インデックス設計やディストリビューションキー設定不要です
– Redshift
– ノード数やインスタンスタイプの選択が必要です
– VACUUMやANALYZE等のメンテナンス作業が必要です
– ソートキーやディストリビューションキーの最適化が必要です
コスト比較例
中規模企業(100GB~1TB)での月間コスト目安
– Snowflake:$200~$800(使用量によって変動)
– Redshift:$180~$600(常時起動の場合)
導入判断のポイント
– 運用工数を削減したい → Snowflake
– AWSエコシステム内で統一したい → Redshift
Databricksとの違い(レイクハウスとの住み分け)
Databricksは「レイクハウス」アーキテクチャを提唱するデータプラットフォームです。
アプローチの違い
– Snowflake:データウェアハウス中心、構造化データに最適化
– Databricks:データレイク中心、機械学習・データサイエンスに特化
得意領域
| 用途 | Snowflake | Databricks |
|---|---|---|
| BI・レポーティング | ◎ | ○ |
| SQL分析 | ◎ | ○ |
| データ共有 | ◎ | △ |
| 機械学習開発 | ○ | ◎ |
| リアルタイム処理 | ○ | ◎ |
| 非構造化データ処理 | ○ | ◎ |
実際の選択基準
– ビジネスユーザーのセルフサービス分析重視 → Snowflake
– データサイエンティストの高度な分析・ML開発重視 → Databricks
– 両方必要 → 連携利用(SnowflakeからDatabricksにデータ連携)
コスト・セキュリティ・運用
従量課金と最適化ポイント
Snowflakeの料金体系は、透明性が高く予測しやすい従量課金制です。
主要な課金要素
1. ストレージコスト
– 「目安として$23~$40/TB/月(リージョン・契約で変動)
– 自動圧縮により実際のデータサイズは大幅削減されます
– Enterprise以上で最大90日間の保持が可能
2. コンピュートコスト
– 仮想ウェアハウスサイズと実行時間に応じた課金です
– 1秒単位での課金(最小1分)
– 例:Mediumサイズで$2/時間(リージョン・契約により変動)
コスト最適化のベストプラクティス
1. 自動停止の設定
sql
— 5分間非使用で自動停止
ALTER WAREHOUSE MY_WH SET AUTO_SUSPEND = 300;
2. 適切なウェアハウスサイズ選択
– 開発・テスト:XS〜S
– 定期レポート:S〜M
– 大量データ処理:L〜XL
– 緊急分析:必要時のみ大型サイズ
3. クエリ最適化
– フィルター条件の最適化
– 不要なカラムの除外(SELECT *の回避)
– 結果セットキャッシュの活用
実際の料金例(参考)
中規模企業(従業員300名、データ量500GB)の月額料金目安
– ストレージ:約$8,000
– コンピュート:約$12,000
– 合計:約$20,000/月
※価格は地域・契約条件・使用パターンにより変動します
セキュリティ機能(暗号化・マスキング・RBAC)
Snowflakeは、エンタープライズレベルのセキュリティ機能を標準で提供しています。
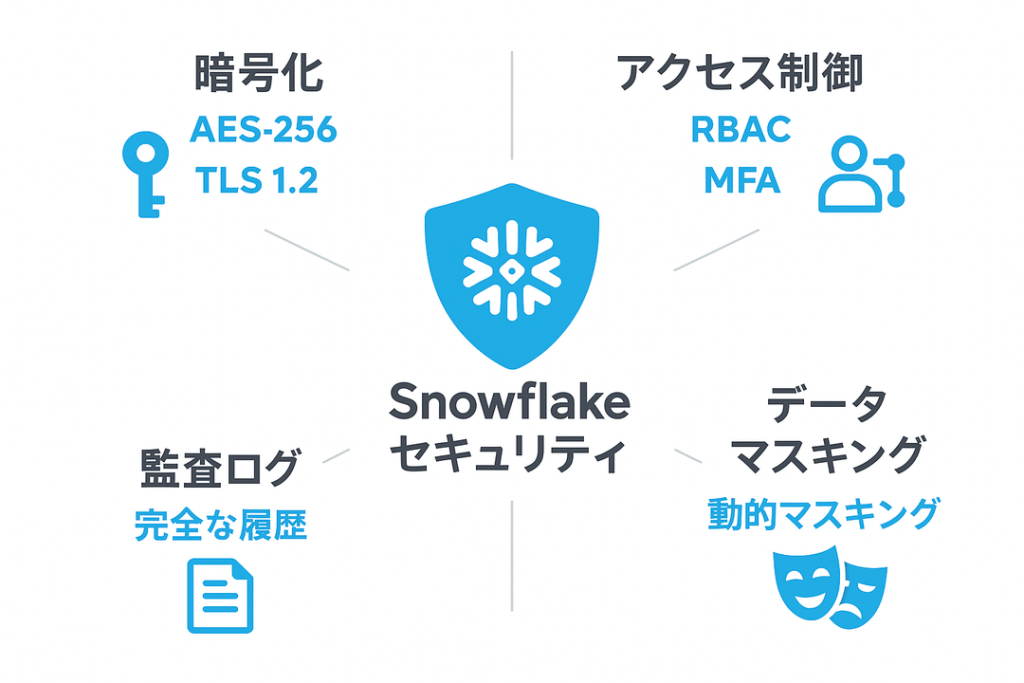
1. 暗号化
– 保存時暗号化:AES-256による自動暗号化
– 転送時暗号化:TLS 1.2以上での通信暗号化
– キー管理:Snowflake管理または顧客管理キー(BYOK)
2. アクセス制御
– ロールベースアクセス制御(RBAC):詳細な権限管理
– マルチファクタ認証(MFA):SSO連携対応
– ネットワークポリシー:IP制限、VPN経由接続制御
3. データマスキング
sql
— 個人情報の動的マスキング例
CREATE MASKING POLICY phone_mask AS (val string) RETURNS string ->
CASE
WHEN CURRENT_ROLE() IN (‘ADMIN’, ‘ANALYST’) THEN val
ELSE ‘XXX-XXXX-‘ || RIGHT(val,4)
END;
4. 監査・ログ機能
– アクセスログ:全てのデータアクセスを記録
– クエリ履歴:実行されたSQL文の完全な履歴
– データ系譜:データの流れと変更履歴の追跡
コンプライアンス対応
– GDPR:個人データの削除・マスキング機能
– HIPAA:医療データ向けの追加セキュリティ
– SOC 2 Type II:第三者監査による統制評価
運用負荷の低減(自動スケール・チューニング不要)
Snowflakeの「Zero Management」思想により、従来のデータウェアハウス運用で必要だった多くの作業が自動化されています。
自動化される運用作業
1. パフォーマンス最適化
– 自動クラスタリング:データの物理配置を自動最適化
– クエリ最適化:統計情報の自動更新とクエリプラン最適化
– キャッシュ管理:結果セット・メタデータキャッシュの自動管理
2. 容量管理
– 自動スケーリング:負荷に応じたコンピュートリソースの自動調整
– ストレージ圧縮:データの自動圧縮とアーカイブ
– 領域管理:不要な一時ファイルの自動削除
3. 可用性・障害対応
– 自動フェイルオーバー:障害時の自動切り替え(設定により)※Business Critical以上のエディションで提供
– データレプリケーション:複数リージョンでの自動データ複製(設定により)
– バックアップ・リストア:定期的な自動バックアップ
従来運用との工数比較(イメージ)
| 作業項目 | 従来DWH | Snowflake |
|---|---|---|
| インデックス設計・メンテナンス | 週8時間 | 0時間(自動) |
| パフォーマンスチューニング | 月40時間 | 月2時間 |
| バックアップ管理 | 週4時間 | 0時間(自動) |
| 容量監視・拡張計画 | 月20時間 | 0時間(自動) |
| アップデート・パッチ適用 | 月16時間 | 0時間(自動) |
運用エンジニアの役割変化
– 従来:システム運用・保守・チューニング
– Snowflake導入後:データ活用戦略・ガバナンス・ユーザーサポート
活用事例
金融・製造・小売におけるSnowflake活用
金融業界での活用例
1. リアルタイムリスク管理
大手銀行では、Snowflakeを使って取引データとマーケットデータを統合し、リアルタイムでのリスク計算を実現しています。従来は夜間バッチで処理していたリスク指標を、日中でもリアルタイムで更新できるようになり、より迅速な投資判断が可能になりました。
2. 規制レポート自動化
金融機関特有の複雑な規制レポートについて、Snowflakeのデータ共有機能を活用し、本社・支社・関連会社間でのデータ連携を自動化。レポート作成期間を短縮させました。
製造業界での活用例
1. IoTデータ活用による予知保全
製造設備のセンサーデータ(温度、振動、電流値等)をSnowflakeに蓄積し、機械学習モデルと組み合わせることで設備故障の予兆検知を実現。設備停止時間を削減し、メンテナンスコストも大幅に削減しました。
2. サプライチェーン最適化
複数の工場・倉庫・物流パートナーのデータをSnowflake上で統合し、リアルタイムでのサプライチェーン可視化を実現。原材料不足や物流遅延の影響を事前に予測し、代替調達先の確保や生産計画の調整を自動化しています。
小売業界での活用例
1. オムニチャネル顧客分析
実店舗のPOSデータ、ECサイトのWebログ、モバイルアプリの利用データを統合し、顧客の購買行動を360度分析。個人の購買傾向に合わせたパーソナライズされた商品推奨により、客単価が向上した事例があります。
2. 在庫最適化と需要予測
過去の売上データ、季節要因、プロモーション効果、外部経済データを組み合わせた高精度な需要予測モデルを構築。過剰在庫を削減し、同時に品切れ率も半減させることに成功しています。
会話型KPIダッシュボード事例
SORAMICHIでは、Snowflakeを基盤とした会話型KPIダッシュボードを開発し、実際に運用しています。
従来の課題
– 複数のBIツールに分散したKPI情報
– データの更新頻度がバラバラで、意思決定に必要な最新情報が得られない
– 非技術者が自由にデータを探索することが困難
Snowflake + AI活用による解決
– 統合データ基盤:Snowflake上に全社のKPIデータを一元化
– 自然言語クエリ:「先月の売上を地域別で教えて」などの日本語での問い合わせが可能
– リアルタイム更新:重要KPIは1時間ごとに自動更新
導入効果
– データ分析にかかる時間が70%短縮
– 非技術者でも自由にデータ探索が可能
– 意思決定のスピードが2倍向上
この会話型KPIダッシュボードの詳細な機能や導入プロセスについては、専用の事例記事で詳しく解説していますので、ぜひご参照ください。
Snowflakeの導入ステップ
PoC(検証)段階のチェックリスト
Snowflakeの導入を検討する際は、まずPoC(Proof of Concept)で実際の効果を検証することが重要です。
PoC実施前の準備チェックリスト
□ 目的・ゴールの明確化
– 解決したい課題の具体化
– 成功判定基準(KPI)の設定
– 検証期間と予算の確定
□ 検証データの準備
– 代表的なデータセットの選定(実データの一部)
– データ品質の事前確認
– 必要なデータ量の見積もり(推奨:本番の10~20%程度)
□ 検証環境の設定
– Snowflakeトライアルアカウントの取得
– 必要な仮想ウェアハウスサイズの決定
– アクセス権限・セキュリティポリシーの設定
□ 検証チームの編成
– プロジェクトマネージャー(1名)
– データエンジニア(1~2名)
– ビジネスユーザー(2~3名)
– インフラ・セキュリティ担当者(1名)
PoC実施中の確認ポイント
1. 性能面の検証
– データ取り込み速度(ETL性能)
– クエリ応答時間(特に複雑な分析クエリ)
– 同時実行時のパフォーマンス
– 自動スケーリングの動作確認
2. 機能面の検証
– 既存BIツールとの連携
– データ共有機能のテスト
– セキュリティ機能の動作確認
– 運用管理機能の使いやすさ
3. コスト面の検証
– 実際の使用量に基づく料金試算
– 既存システムとの比較
– スケールアップ時のコスト変化
PoC成功のための重要なポイント
– 実際のビジネス課題に基づいたユースケースで検証
– 本番に近い条件でのテスト実施
– 定量的な評価(数値での効果測定)
– ユーザビリティの確認(エンドユーザーの使いやすさ)
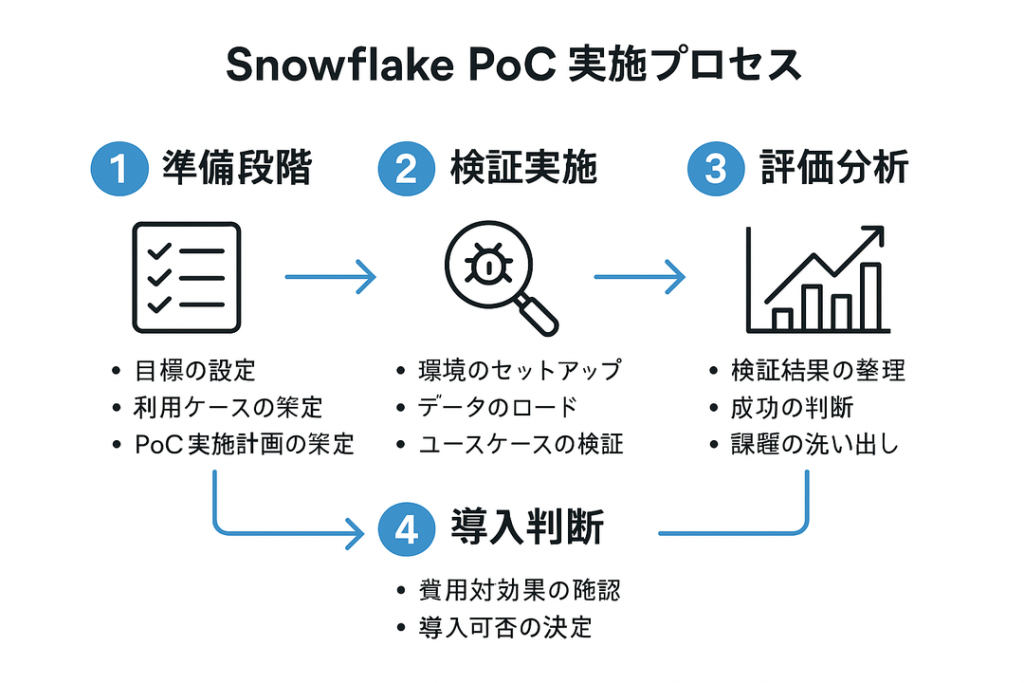
本番展開のステップ
PoCで効果が確認できた後の本番展開は、以下のステップで進めることを推奨します。
Phase 1: 基盤構築(1~2ヶ月)
インフラ設計・構築
– 本番環境のアーキテクチャ設計
– ネットワーク・セキュリティ設定
– 監視・ログ収集の仕組み構築
– ディザスタリカバリ計画の策定
データ移行計画
– 既存データの棚卸しと移行優先度決定
– ETLプロセスの設計・開発
– データ品質チェックの仕組み構築
– 段階的移行スケジュールの策定
Phase 2: パイロット運用(2~3ヶ月)
限定的な本番運用開始
– 特定部門・用途での先行運用
– エンドユーザーへのトレーニング実施
– 運用手順書の整備
– 問題・改善点の洗い出し
運用体制の確立
– 運用チームの役割分担明確化
– エスカレーション手順の整備
– 定期的なレビュー会の実施
Phase 3: 全社展開(3~6ヶ月)
段階的なユーザー拡大
– 部門ごとの順次展開
– 既存システムからの段階的移行
– ユーザーサポート体制の強化
最適化・改善
– パフォーマンスチューニング
– コスト最適化の実施
– 新機能・追加要件への対応
本番展開での注意点
– 一度に全てを移行しない:リスクを分散し、段階的に実施
– ユーザー教育を重視:新しいツールへの習熟度が成功の鍵
– 継続的な改善:運用開始後も定期的な見直しと最適化
FAQ
料金は高いのか?
Q: Snowflakeの料金は他のサービスと比較して高いのでしょうか?
A: トータルコストで考えると、多くの場合でコスト削減につながります。
料金だけでの比較は不十分な理由
1. 運用コストの大幅削減
– 人件費削減:運用・保守の工数が80%削減される事例が多数
– インフラ管理費:クラウドネイティブで物理サーバー管理が不要
– ライセンス統合:複数のツールを統合することでライセンス費用削減
2. 従量課金によるコスト最適化
– 使った分だけ課金:アイドル時間のコストゼロ
– 自動スケーリング:ピーク時のみリソース拡張
– 予期しない高額請求の回避:事前のコスト上限設定が可能
コスト比較例(月間500GBデータ、20ユーザー)
※一例:月間500GBデータ・20ユーザーの場合
| 項目 | 従来オンプレミス | Snowflake |
| 初期導入費用 | ¥5,000,000 | ¥0 |
|---|---|---|
| 月間システム費用 | ¥300,000 | ¥150,000 |
| 月間運用人件費 | ¥400,000 | ¥100,000 |
| 年間総費用 | ¥13,400,000 | ¥3,000,000 |
コスト削減のポイント
– 3年以上の利用であればほぼ確実にコスト削減
– 運用工数削減が最大の削減要因
– スケーラビリティにより将来の拡張コストも抑制
どの規模から導入すべきか?
Q: 会社の規模やデータ量がどの程度になったらSnowflakeを検討すべきでしょうか?
A: データ量よりも「データ活用の課題」があるかどうかが重要な判断基準です。
導入を検討すべき状況
1. データ量の観点
– 50GB以上:基本的な効果を実感可能
– 500GB以上:大きなコストメリットを実感
– 5TB以上:従来システムでは困難な処理が可能
2. 組織規模の観点
– 従業員100名以上:複数部門でのデータ活用ニーズ
– 分析ユーザー10名以上:同時アクセスでの性能メリット
– IT担当者2名以下:運用負荷削減の効果が大きい
3. ビジネス課題の観点(より重要)
– リアルタイム分析の必要性
– 部門間でのデータ共有課題
– 既存DWHの性能・拡張性に限界
– 運用工数・コストの増大
規模別の導入パターン(一般的な目安として)
小規模企業(従業員〜100名)
– 推奨アプローチ:特定用途でのスモールスタート
– 典型的ユースケース:顧客分析、売上レポート自動化
– 月額目安:$500~$2,000
中規模企業(従業員100~1,000名)
– 推奨アプローチ:部門別段階導入
– 典型的ユースケース:全社BI基盤、データ統合
– 月額目安:$2,000~$10,000
大規模企業(従業員1,000名以上)
– 推奨アプローチ:エンタープライズ機能フル活用
– 典型的ユースケース:データレイク統合、グローバル展開
– 月額目安:$10,000以上
「まだ早い」と判断される場合
– データがExcel管理で十分な規模
– 分析ユーザーが1~2名のみ
– 月間データ更新が1~2回程度
競合サービスからの移行は可能か?
Q: 現在他のクラウドDWHサービスを使用していますが、Snowflakeへの移行は可能でしょうか?
A: ほぼ全ての主要サービスからの移行が可能で、多くの支援ツール・パートナーが存在します。
まとめ
Snowflakeは、従来のデータウェアハウスの常識を覆す革新的なクラウドデータプラットフォームです。本記事で解説した通り、その革新性は以下の4つの柱に集約されます。
Snowflakeの核心的な強み
1. 分離アーキテクチャによる柔軟性
ストレージとコンピュートの完全分離により、コスト効率と処理性能を両立。必要な時に必要な分だけリソースを使用でき、従来の固定コスト構造から脱却できます。
2. 圧倒的なスケーラビリティ
数秒での自動スケーリングと無制限のデータ容量により、ビジネスの成長に合わせて柔軟に拡張。ピーク時の処理にも余裕で対応できます。
3. 革新的なデータ共有機能
ゼロコピー共有とSnowflake Marketplaceにより、組織間でのセキュアなデータ連携が簡単に実現。データサイロを解消し、新たなビジネス価値を創出できます。
4. 運用負荷の大幅削減
自動最適化・自動スケーリング・自動メンテナンスにより、IT運用工数を80%削減。エンジニアはシステム運用ではなく、データ活用戦略に集中できます。
競合比較での明確なポジション
– vs BigQuery:マルチクラウド対応と同時実行性能で優位
– vs Redshift:運用負荷の軽さと柔軟性で大きく勝る
– vs Databricks:BI・分析基盤としての使いやすさで差別化
導入検討時のチェックリスト
□ データ量が50GB以上、または今後の急速な増加が見込まれる
□ 複数部門でのデータ活用ニーズがある
□ リアルタイム性や同時アクセス性能に課題がある
□ 既存DWHの運用コスト・工数に負担を感じている
□ 外部パートナーとのデータ共有が必要
3つ以上に該当する場合は、Snowflake導入により大きなメリットを得られる可能性が高いでしょう。
次のアクションステップ
1. 無料トライアルの実施
Snowflake公式サイトから無料トライアルを開始し、実際のデータで検証してみることをお勧めします。
2. PoCの計画立案
具体的なビジネス課題に基づいたPoC計画を策定し、定量的な効果測定を行いましょう。
3. 専門パートナーとの相談
導入成功率を高めるために、実績豊富な専門パートナーとの早期相談をお勧めします。
SORAMICHIでは、Snowflakeの導入検討から運用まで、お客様の状況に合わせた包括的な支援を提供しています。戦略策定から技術実装、継続的な運用改善まで、データ活用の成果最大化に向けて伴走いたします。
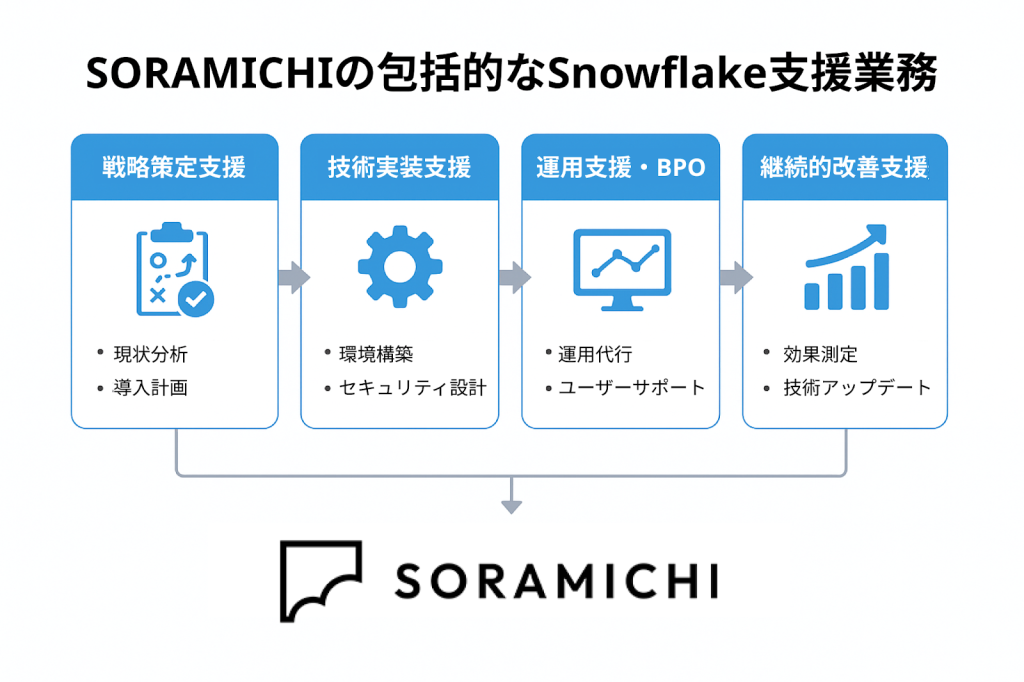
Snowflakeを活用したデータドリブン経営の実現に向けて、まずはお気軽にご相談ください。

Snowflake導入・運用支援
データ基盤の構築から活用定着までを一気通貫で支援します
Snowflakeに関するQ&A
- Snowflakeとは何ですか?
-
クラウド上で提供されるデータウェアハウス(DWH)サービスです。
2012年にアメリカで創業され、AWS・Azure・Google Cloudの3大クラウド上で稼働。営業・顧客・財務など分散したデータを一元管理できる「データクラウド」を提供します。
- Snowflakeの最大の特徴は何ですか?
-
ストレージとコンピュートを完全分離した独自アーキテクチャです。
従来のDWHは保存と処理が一体化していましたが、Snowflakeは独立してスケール可能。必要な時だけコンピュートを増強でき、コスト最適化を実現します。
- BigQueryやRedshiftとの違いは何ですか?
-
マルチクラウド対応・同時実行性能・運用負荷の軽さで優位性があります。
BigQueryはGoogle Cloud前提、RedshiftはAWS前提でチューニングも必要。Snowflakeは3大クラウドに対応し、インデックス設計やメンテナンス作業が不要なため運用工数を大幅に削減できます。
- 導入コストの目安はどれくらいですか?
-
中規模企業で月額約$20,000が一つの目安です。
従業員300名・データ量500GB程度のケースで、ストレージ約$8,000+コンピュート約$12,000の内訳。1秒単位の従量課金と自動停止機能により、無駄なコストが発生しにくい設計です。
- どのくらいの規模から導入を検討すべきですか?
-
データ量よりも「データ活用の課題」があるかどうかが重要な判断基準です。
データ量50GB以上や複数部門での活用ニーズがあれば、導入効果を実感しやすくなります。




関連記事
-
 dbt on Snowflakeによるデータ基盤モダナイゼーション検証【大手ヘルスケア/ライフサイエンス企業企業様】
dbt on Snowflakeによるデータ基盤モダナイゼーション検証【大手ヘルスケア/ライフサイエンス企業企業様】 -
【2025年11月更新】10月度のWeb広告関連のアップデート情報まとめ
-
【徹底解説】Snowflake料金ガイド|エディション比較・クレジット・最適化の実践術
-
「KARTE」の機能を活用したNarrative Tracking(ナラティブ・トラッキング)分析を解説
-
KARTEを使ってWebサイトを改善!ABテスト機能をご紹介
-
顧客体験を向上させる!Brazeを活用した次世代マーケティング
-
会話型KPIダッシュボードの実現: Snowflake×Streamlit×Claudeの最強組み合わせ
-
ユーザー情報変数を利用して、CXを改善するための技術検証を実施してみた話






